
Introduction
Natural Language Processing is a field widely growing in popularity these days. A large number of companies worldwide are leveraging the power of Natural language processing and the innovations in the field to extract meaningful insights from text and to generate text. In the past couple of years, with Google Brain’s Attention is All You Need paper, the transformers architecture has revolutionized this field even further. In almost all the classic NLP tasks like Machine translation, Question Answering, Reading Comprehension, Common Sense Reasoning and Summarization, a Transformer-based architecture beat the State-of-the-art. Since then, all tech giants like Google, Facebook, OpenAI, Microsoft have been experimenting with transformers in various applications.
One such application that made headlines was the Language Generation task, wherein Transformers were able to generate meaningful text given a prompt. One of the first headliners was HuggingFace with their Talk to Transformers web page, where anyone could generate their own AI-generated text by giving a prompt. Here, we will explore how transformers are used in Language generation. Also later in the blog, we will share code for how to train a transformer langauge model on your own corpus. We trained a GPT-2 model on Harry Potter books. The trained model is able to generate text like Harry Potter books when presented with an input. See example below. Full code is available on my Github.
Interesting observations: 1. Model has learnt that Hagrid has large feet!, 2. Gilderoy Lockhart writes books, 3. New books can appear in Hogwarts book shelves.

What are Language Models?
A language model is a model which learns to predict the probability of a sequence of words. In simpler words, language models essentially predict the next word given some text. By training language models on specific texts, it is possible to make the model learn the writing style of that text. Although various kinds of language models existed in the past, they became much more powerful after the introduction of Transformers by the Google Brain team(“Attention is All You Need”).
With the advent of transformers, multiple groups were able to create and train custom architectures for language models. One such group was the Open AI community who introduced GPT(short for Generative Pre-training Transformer). The GPT model was released in 2018, but unfortunately , soon after it’s release, it was knocked off the GLUE leaderboard by BERT. But, in February, 2019, OpenAI scaled up their model by training on a whopping 1.5 billion parameters which in turn gave it human-like writing capabilities. It was named “OpenAI’s GPT-2”.
Transformers and GPT-2
Transformers is the basic architecture behind the language models. A transformer mainly consists of two basic components : encoders and decoders.
As seen in the diagram above, both Encoder and Decoders have modules that can be stacked together, as represented by Nx. Mainly, both Encoders and Decoders have the Feed-forward and Multi-Head attention components.
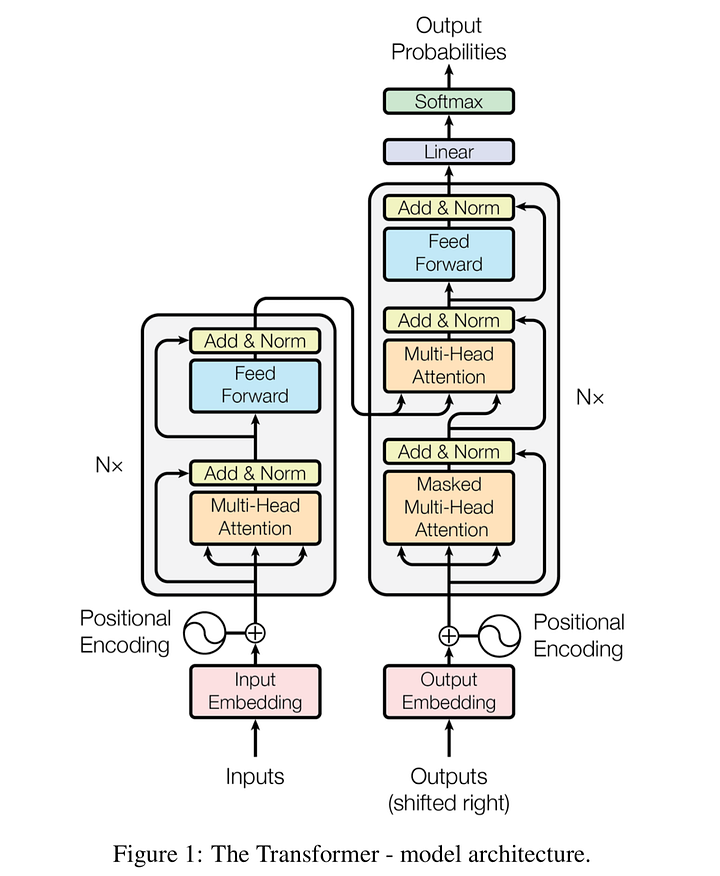
The inputs and outputs are embedded into an n-dimensional space before passing them on to the components. One important step in the input and output components is the Positional Encoding wherein we provide information regarding the position of the word to the transformer. These encodings are added to the embeddings of each word and the resulting embeddings are passed to the transformer.
An encoder block has multiple encoder blocks and the decoder block has the same number of decoder blocks. The number of blocks is a hyperparameter which can be tuned while training.
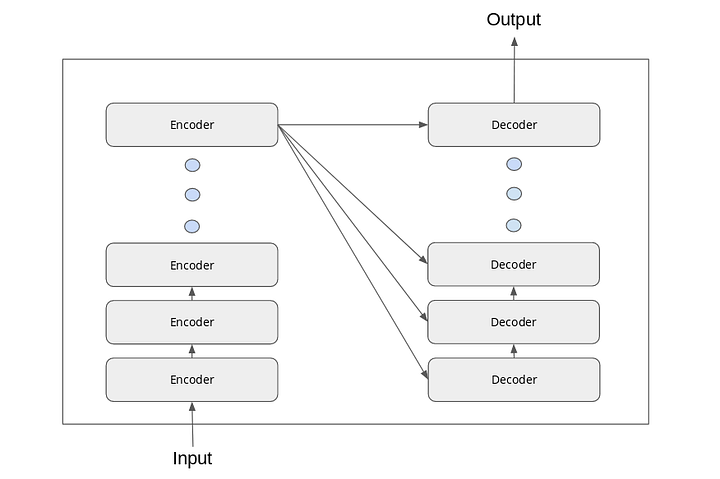
The working of the encoder-decoder stack is described as follows:
- The input embeddings are passed to the first encoder.
- The embeddings are transformed after passing through the feed-forward and self-attention layers of the encoder.
- The transformed output is passed to the next encoder.
- The last encoder passes the output to all the decoders in the stack.
The self-attention layer in the encoder and decoders play a very important role in the processing of the words. It enables the model to look at other words in the input sequence to get a better understanding of the context of the current word.
Apart from the Feed-forward and Attention component, decoders also have another attention layer (Masked multi-head attention) which helps the decoder focus on specific parts of the input sequence.
OpenAI extended the Transformers concept for the Language generation task in two iterations : GPT and GPT-2. GPT architecture used 12-layer decoders with masked self-attention heads and trained for 100 epochs. With GPT-2 model, the vocabulary was expanded to 50,257 words. There was also an increase in the context size from 512 to 1024 tokens and a larger batchsize of 512 was used.
Diving into Code!
In this blog, we will leverage the awesome HuggingFace’s transformer repository to train our own GPT-2 model on text from Harry Potter books. We will provide a sentence prompt to the model and the model will complete the text. In order to train the model, we will feed all Harry Potter books for the model to learn from them.
We have cloned the huggingface repo and updated the code to correctly perform language model training and inference. Please follow along on my Github repo.
Downloading Harry Potter books and preprocessing the text
The first step is downloading all the harry potter books and preprocessing the text. We scraped the text from the first 4books and merged it together. Then we wrote a short piece of code to remove unnecessary text like the page numbers from the merged text. Finally the GPT-2 model needs both train and validation text. So we take first 90% of the data as training sample and the remaining as validation sample. The preprocessing code is here.
Training a GPT-2 model
To train the model we use the script — run_lm_finetuning.py. The script takes as input the model type and its size, as well as the preprocessed text. The script also provides a bunch of hyperparameters that can be tweaked in order to customize the training process. The code snippet for training is:
cd examples ## Move to examples directory
python run_lm_finetuning.py \
--output_dir=output \
--model_type=gpt2 \
--model_name_or_path=gpt2-medium \
--do_train \
--train_data_file='input_data/train_harry.txt' \
--do_eval \
--eval_data_file='input_data/val_harry.txt'\
--overwrite_output_dir\
--block_size=200\
--per_gpu_train_batch_size=1\
--save_steps 5000\
--num_train_epochs=2
The parameters used in the code is as follows:
The parameters used here are explained as follows:
- Output_dir is the name of the folder where the model weights are stored.
- Model_type is the name of the model. In our case we are training on the gpt-2 architecture, we use ‘gpt-2’.
- Model_name_or_path is where we define the model size to be used.(’gpt2’ for small, ‘gpt2-medium’ for a medium model and ‘gpt2-large’ for a large model)
- Do_train is essentially a flag which we define to train the model.
- train_data_file is used to specify the training file name.
- Do_eval is a flag which we define whether to evaluate the model or not, if we don’t define this, there would not be a perplexity score calculated.
- Eval_data_file is used to specify the test file name.
- gradient_accumulation_steps is a parameter used to define the number of updates steps to accumulate before performing a backward/update pass.
- Overwrite_output_dir is a parameter which when specified overwrites the output directory with new weights.
- block_size is a parameter according to which the training dataset will be truncated in block of this size for training.
- Per_gpu_train_batch_size is the batch size per GPU/CPU for training.
- Save steps — allows you to periodically save weights before the final set of weights
- num_epochs — Determines how many epochs are run.
We trained a medium GPT-2 model on the text of 4harry potter books. This model took only 10 min to train on a GTX 1080 Ti. The perplexity score of the trained model was 12.71. Read this blog to learn more about Perplexity score. But remember, lower the score, the better the model is.
Inference Script
Once the model is trained, we can run inference using it. The inference script is run_generation.py
For doing inference, the input text is first encoded through the tokenizer , then the result is passed through a generate function where the generation of text happens based on parameters like temperature, top-p and k values.
The code snippet for doing inference is:
cd examples
python run_generation.py --model_type gpt2 --model_name_or_path output --length 300 --prompt "Malfoy hadn’t noticed anything."
These parameters are explained below:
- model_name_or_path : This is the folder path where the weights of the trained model are stored.
- Prompt: This is the input prompt based on which the rest of the text will be generated.
- Length: This parameter controls the length of characters to be generated in the output.
Some additional parameters that can be tweaked are:
- Temperature: This parameter decides how adventurous the model gets with its word selection.

- p : This parameter controls how broad a range of continuations are considered. Set it high to consider all continuations. Set it low to just consider likely continuations. The overall effect is similar to temperature, but more subtle.
- k: This parameter controls the number of beams or parallel searches through the sequence of probabilities. Higher the value, better the accuracy , but slower the speed.
- Seed: This parameter helps in setting the seed.
- Repetition_penalty: This parameter penalizes the model for repeating the words chosen.
One more example of model output is below. Very interesting to see the story around the cloaked figure that this model is creating.

Conclusion
The advent of transformers has truly revolutionized many Natural language processing tasks, and language generation is one of them. The potential of a language generation model is huge and can be leveraged in many applications like chatbots, long answer generation, writing automated reports and many more. In this blog, we understood the working of transformers, how they are used in language generation and some examples of how anyone can leverage these architectures to train their own language model and generate text.
I am extremely passionate about NLP, Transformers and deep learning in general. I have my own deep learning consultancy and love to work on interesting problems. I have helped many startups deploy innovative AI based solutions. Check us out at — https://deeplearninganalytics.org/.
You can also see my other writings at: https://medium.com/@priya.dwivedi
If you have a project that we can collaborate on, then please contact me through my website or at info@deeplearninganalytics.org
References
- Transformers — Attention is all you need. This is the paper that started it all
- BERT
- GPT-2 model
- Hugging Face Repo