Introduction
Fake news, junk news or deliberate distributed deception has become a real issue with today’s technologies that allow for anyone to easily upload news and share it widely across social platforms. The Pew Research Center found that 44% of Americans get their news from Facebook. In the wake of the surprise outcome of the 2016 Presidential Election, Facebook and Twitter have come under increased scrunity to block fake news content from their platform.
I came across an interesting study that looked into the spread of fake information through Twitter. The study found that “Falsehood diffused significantly farther, faster, deeper, and more broadly than the truth in all categories of information.” It also found that “the effects were more pronounced for false political news than for false news about terrorism, natural disasters, science, urban legends, or financial information.”
In this blog, we show how cutting edge NLP models like the BERT Transformer model can be used to separate real vs fake tweets. We leverage a powerful but easy to use library called SimpleTransformers to train BERT and other transformer models with just a few lines of code. Our complete code is open sourced on my Github.
Data set
For this blog, we used the data from the Kaggle Competition — Real or Not?NLP with Disaster tweets.
The data set consists of 10,000 tweets that have been hand classified. Each sample in the train and test set has the following information:
- The text of a tweet
- A keyword from that tweet (although this may be blank!)
- The location the tweet was sent from (may also be blank)
The goal of the competition is to use the above to predict whether a given tweet is about a real disaster or not.
Model Architecture
We will use a BERT Transformer model to do this classification. Lets first talk in brief about the Transformers Architecture
Transformers
Transformers have become the the basic building block of most state-of-the-art architectures in NLP. The architecture consists of two main components : a set of Encoders chained together and a set of Decoders chained together. The function of each encoder is to process its input vectors to generate encodings, which contain information about the parts of the inputs which are relevant to each other. It passes its set of generated encodings to the next encoder as inputs. Each decoder does the opposite, taking all the encodings and processing them, using their incorporated contextual information to generate an output sequence. Both the encoder and decoder makes use of an attention mechanism.
Each encoder consists of two major components: a self-attention mechanism and a feed-forward neural network. The self-attention mechanism takes in a set of input encodings from the previous encoder and weighs their relevance to each other to generate a set of output encodings. The feed-forward neural network then further processes each output encoding individually. These output encodings are finally passed to the next encoder as its input, as well as to the decoders.
Each decoder consists of three major components: a self-attention mechanism, an attention mechanism over the encodings, and a feed-forward neural network. The decoder functions in a similar fashion to the encoder, but an additional attention mechanism is inserted which instead draws relevant information from the encodings generated by the encoders.To understand more on Transformers you can refer Attention is all you need paper .
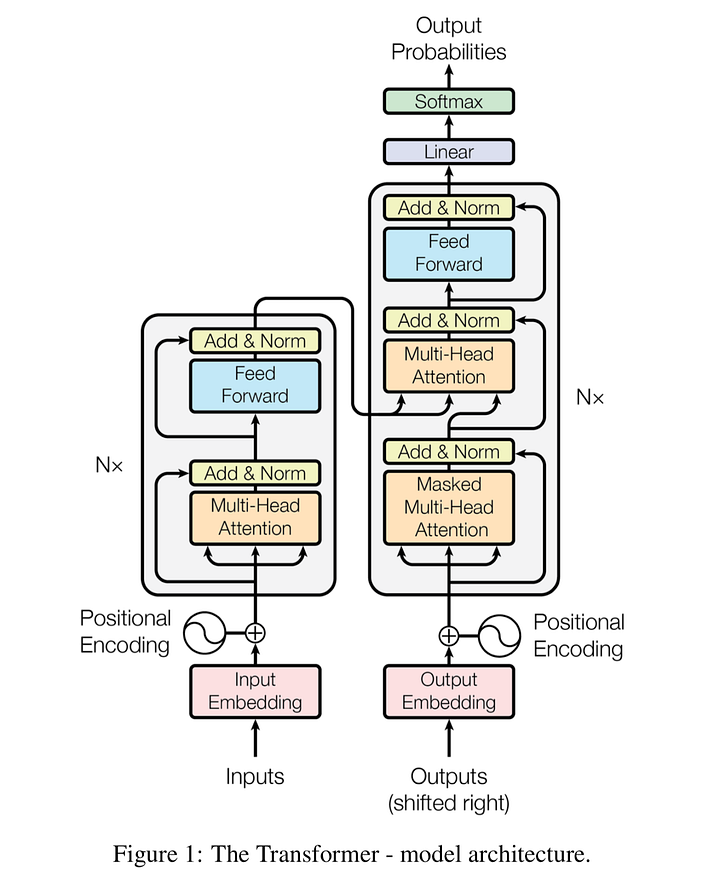
BERT Model
BERT (Bidirectional Encoder Representations from Transformers) is a very popular Transformer Model. BERT’s key technical innovation is applying the bidirectional training to a Transformer Architecture. This is in contrast to previous efforts which looked at a text sequence either from left to right or combined left-to-right and right-to-left training. The paper’s results show that a language model which is bidirectionally trained can have a deeper sense of language context and flow than single-direction language models. Before feeding word sequences into BERT, 15% of the words in each sequence are replaced with a [MASK] token. The model then attempts to predict the original value of the masked words, based on the context provided by the other, non-masked, words in the sequence. You can read more about BERT in their paper here.
Simple Transformers
Simple Transformer is a wrapper around the Transformers library from Hugging Face. Simple Transformers can be found at this Github link. The main goal of Simple Transformers is to abstract away many of the implementation and technical details around Transformer models. This is very useful if you want to quickly train a transformer model on your data to see if it works before digging into more details.
Simple Transformers library is written so that you can initialize, train and evaluate a Transformer model on your data set with just a few lines of code. Sounds interesting? Let’s see how it can be done.
Model Build
First, please download and install the Simple Transformer library. Instructions can be found at this link.
Clean up the Tweets data
Before we start doing text classification of the tweet we want to clean the tweets as much as possible . We start by removing things like hashtags, hyperlinks, HTML characters, tickers, emojis etc.
For Now we will drop columns “Keyboard” and “location” and just use the tweets text information as this blog is about text based classification.
Our method, clean_dataset does this. Full code on Github link.
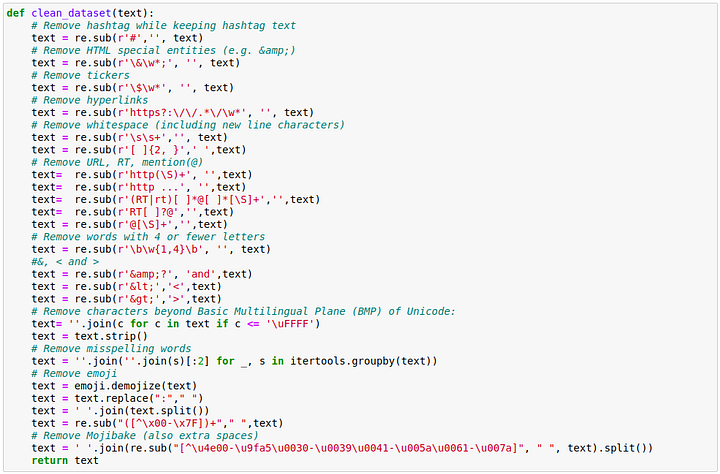
We then use Sklearn to split the data set into 80% train and 20% validation set.
Train BERT Model
To start training using SimpleTransformers, first set up the arguments for training. Complete code is also on my Github at this link.
train_args = {
‘evaluate_during_training’: True,
‘logging_steps’: 100,
‘num_train_epochs’: 2,
‘evaluate_during_training_steps’: 100,
‘save_eval_checkpoints’: False,
‘train_batch_size’: 32,
‘eval_batch_size’: 64,
‘overwrite_output_dir’: True,
‘fp16’: False,
‘wandb_project’: “visualization-demo”
}
Next create a BERT Model class with the above arguments
model_BERT = ClassificationModel(‘bert’, ‘bert-base-cased’, num_labels=2, use_cuda=True, cuda_device=0, args=train_args)
Training and Evaluating the model are also just one liners. I have a 1080Ti GPU and the model takes a few minutes to train on my machine
### Train BERT Model
model_BERT.train_model(train_df_clean, eval_df=eval_df_clean)
### Evaluate BERT Model
result, model_outputs, wrong_predictions = model_BERT.eval_model(eval_df_clean, acc=sklearn.metrics.accuracy_score)
The evaluation script returns the following statistics
{‘mcc’: 0.5915974149823142, ‘tp’: 466, ‘tn’: 755, ‘fp’: 119, ‘fn’: 183, ‘eval_loss’: 0.45270544787247974, ‘acc’: 0.8017071569271176}
We get an accuracy score of ~80% as well as the numbers in confusion matrix the True Positive (tp), True Negative (tn), False Positive (fp) and False Negative (fn). MCC stands for Matthews correlation coefficient. It is especially useful in measuring the quality of binary classification. MCC values can lie b/w -1 and+1 with higher values indicating a better score
Train Other Transformer Models — Roberta and Albert
Simpletransformers can be used to train other transformer models too. Below is the current list of supported models:
- BERT
- RoBERTa
- XLNet
- XLM
- DistilBERT
- ALBERT
- CamemBERT
- XLM-RoBERTa
- FlauBERT
I used the above code to also train a Roberta and Albert model. The main change in the code was creating a model for them as below
### Roberta model
model_Roberta = ClassificationModel(‘roberta’, ‘roberta-base’, num_labels=2, use_cuda=True, cuda_device=0, args=train_args)
## Albert model
model_albert = ClassificationModel(‘albert’, ‘albert-base-v2’, num_labels=2, use_cuda=True, cuda_device=0, args=train_args)
Its amazing how simple it is to train multiple models with SimpleTransformers code. I personally got the best results from Roberta Model
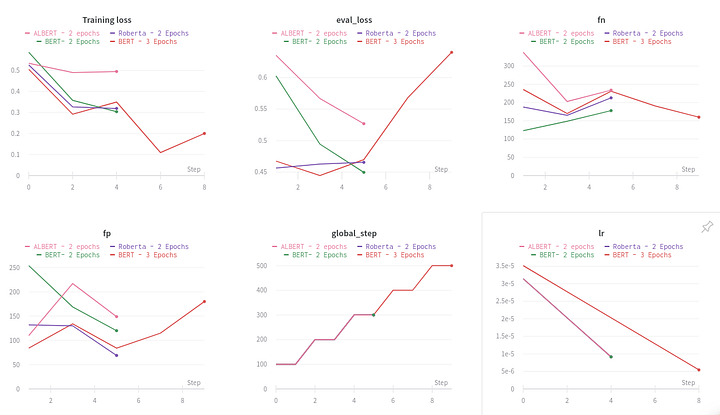
Visualizing the training process
SimpleTransformers has inbuilt support through Weights and Biases to allow visualization of the training in a browser. This is very similar to Tensorboard but easier to setup!
To get started first install wandb as
pip install wandb
My train args create a project called “visualization demo” through wandb as ‘wandb_project’: “visualization-demo”. You have to login through wandb and get an API key which you can input in the Jupyter notebook. That’s all!. You now get a link that allows you to follow training through different experiments in the browser. See results of my visualization demo project at the link.
Wandb shares stats like train loss, eval loss, fn, fp, tn, tp and mcc metrics as the model trains. Very cool!
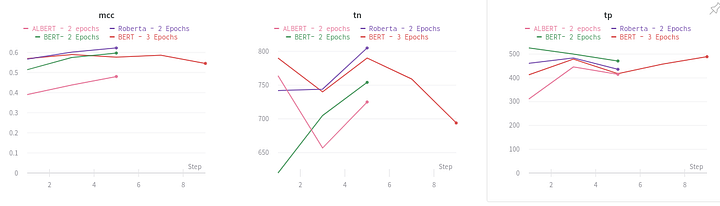
Evaluating Model on random tweets
Evaluating the trained model on random tweet text is also quite simple. We start by cleaning the text, applying the same text processing done at training time.
## Clean Tweet Text
test_tweet1 = “#COVID19 will spread across U.S. in coming weeks. We’ll get past it, but must focus on limiting the epidemic, and preserving life”
test_tweet1 = remove_contractions(test_tweet1)
test_tweet1 = clean_dataset(test_tweet1)
## Run predictions through the model
predictions, _ = model_Roberta.predict([test_tweet1])
response_dict = {0: ‘Fake’, 1: ‘Real’}
print(“Prediction is: “, response_dict[predictions[0]])
The model was able to correctly predict that
“#COVID19 will spread across U.S. in coming weeks. We’ll get past it, but must focus on limiting the epidemic, and preserving life” — REAL Tweet
“Everything is ABLAZE. Please run!!” — FAKE Tweet
Conclusion
Transformers have taken NLP to the next level with state of the art performance on tasks like classification, question answering, named entity recognition. In this blog, we show that you can train your own BERT classifier model with just a few lines of code. We hope you pull the code and give this a shot.
I am extremely passionate about NLP, Transformers and deep learning in general. I have my own deep learning consultancy and love to work on interesting problems. I have helped many startups deploy innovative AI based solutions. Check us out at — https://deeplearninganalytics.org/.
You can also see my other writings at: https://medium.com/@priya.dwivedi
If you have a project that we can collaborate on, then please contact me through my website or at info@deeplearninganalytics.org
References
- Transformer Model Paper: https://arxiv.org/abs/1706.03762
- BERT Model Explained: https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
- Kaggle — Real vs Fake Tweets competition.
- Study on Spread of False News on Twitter
- Good tutorial on Simple Transformers and Visualization using Wandb