
Introduction
Question Answering is a popular application of NLP. Transformer models trained on big datasets have dramatically improved the state-of-the-art results on Question Answering.
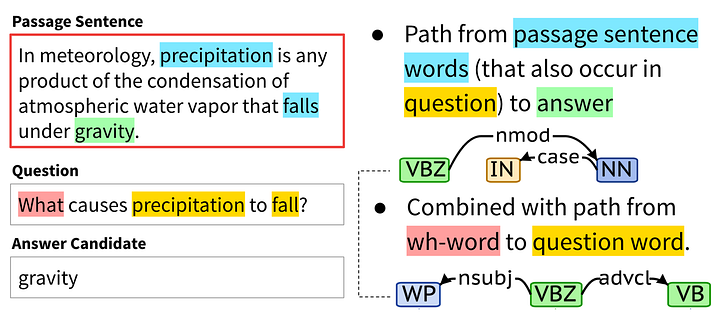
The question answering task can be formulated in many ways. The most common application is an extractive question answering on a small context. The SQuAD dataset is a popular dataset where given a passage and a question, the model selects the word(s) representing the answer. This is illustrated in Fig 1 below.
However, most practical applications of question answering involve very long texts like a full website or many documents in the database. Question Answering with voice assistants like Google Home/Alexa involves searching through a massive set of documents on the web to get the right answer.
In this blog, we build a search and question answering application using Haystack. This application searches through Physics, Biology and Chemistry textbooks from Grades 10, 11 and 12 to answer user questions. The code is made publicly available on Github here. You can also use the Colab notebook here to test the model out.
Search and Ranking
So, how do we retrieve answers from a massive database?
We break the process of Question Answering into two steps:
- Search and Ranking: Retrieving likely passages from our database that may have the answer
- Reading Comprehension: Finding the answer among the retrieved passages
This process is also illustrated in Fig 2 below.
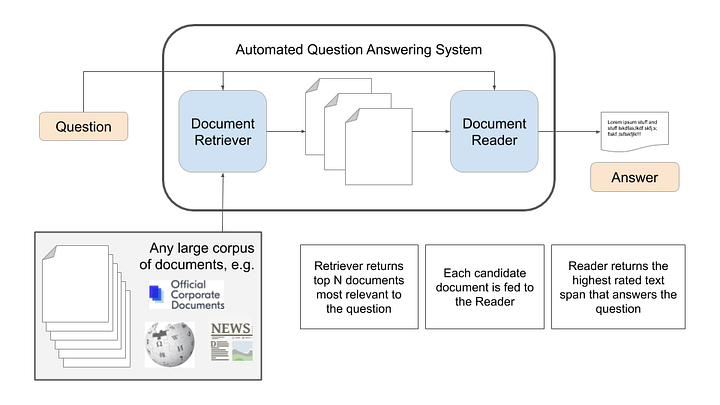
The search and ranking process usually involves indexing the data into a database like ElasticSearch or FAISS. These databases have implemented algorithms for very fast search across millions of records. The search can be done using the words in the query using TFIDF or BM25, or the search can be done considering the semantic meaning of the text by embedding the text or a combination of these can also be used. In our code, we use a TFIDF based retriever from Haystack. The entire database is uploaded to an ElasticSearch database and the search is done using a TFIDF Retriever which sorts results by score. To learn about different types of searches, please check out this blog by Haystack.
The top-k passages from the retriever are then sent to a Question-Answering model to get possible answers. In this blog, we try 2 models — 1. BERT model trained on SQuAD dataset and 2. A Roberta model trained on the SQuAD dataset. The reader in Haystack helps load these models and get the top K answers by running these models on the retrieved passages from the search.
Building our Question-Answering Application
We download PDF files from the NCERT website. There are about 130 PDF chapters spanning 2500 pages. We have created a combined PDF which is available on google drive here. If using Colab upload this PDF to your environment.
We use the HayStack PDF converter to read the PDF to a text file
converter = PDFToTextConverter(remove_numeric_tables=True, valid_languages=["en"])
doc_pdf = converter.convert(file_path="/content/converter_merged.pdf", meta=None)[0]
Then we split the document into many smaller documents using the PreProcessor class in Haystack.
preprocessor = PreProcessor(
clean_empty_lines=True,
clean_whitespace=True,
clean_header_footer=False,
split_by="word",
split_length=100,
split_respect_sentence_boundary=True)
dict1 = preprocessor.process([doc_pdf])
Each document is about 100 words long. The pre-processor creates 10K documents.
Next, we index these documents to an ElasticSearch database and initialize a TFIDF retriever.
retriever = TfidfRetriever(document_store=document_store)
document_store.write_documents(dict1)
The retriever will run a search against the documents in the ElasticSearch database and rank the results.
Next, we initialize the Question-Answering pipeline. We can load any Question Answering model on the HuggingFace hub using the FARM or Transformer Reader.
reader = TransformersReader(model_name_or_path="deepset/bert-large-uncased-whole-word-masking-squad2", tokenizer="bert-base-uncased", use_gpu=-1)
Finally, we combine the retriever and ranker into a pipeline to run them together.
from haystack.pipelines import ExtractiveQAPipeline
pipe = ExtractiveQAPipeline(reader, retriever)
That’s all! We are now ready to test our pipeline.

Testing the Pipeline
To test the pipeline, we run our questions through it setting our preferences for top_k results from retriever and reader.
prediction = pipe.run(query="What is ohm's law?", params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 3}}
When we ask the pipeline to explain Ohm’s law, the top results are quite relevant.

Next, we ask about hydropower generation.
prediction = pipe.run(query="What is hydro power generation?", params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 3}}

We have tested the pipeline on many questions and it performs quite well. It is fun to read on a new topic in the source PDFs and ask a question related to it. Often, I find that the paragraph I read was in the top 3 results.
My experimentation suggested mostly similar results from BERT and Roberta with Roberta being slightly better.
Please use the code on Colab or Github to run your own STEM questions through the model.
Conclusion
This blog shows how question answering can be used for many practical applications involving long texts like a database with PDFs, or through a website containing many articles. We use Haystack here to build a relatively simple application. Haystack has many levers to adjust and fine-tune to further improve performance. I hope you pull down the code and run your own experiments. Please share your experience in the comments below.
At Deep Learning Analytics, we are extremely passionate about using Machine Learning to solve real-world problems. We have helped many businesses deploy innovative AI-based solutions. Contact us through our website here if you see an opportunity to collaborate.