
Introduction
Grammatical Error Correction (GEC) systems aim to correct grammatical mistakes in the text. Grammarly is an example of such a grammar correction product. Error correction can improve the quality of written text in emails, blogs and chats.
GEC task can be thought of as a sequence to sequence task where a Transformer model is trained to take an ungrammatical sentence as input and return a grammatically correct sentence. In this blog, we show how you can train such a model and use Weights and Biases to monitor the performance of the model as it trains. We have also released our trained model on Spaces here for experimentation. The code is also made public on Colab here and Github here.
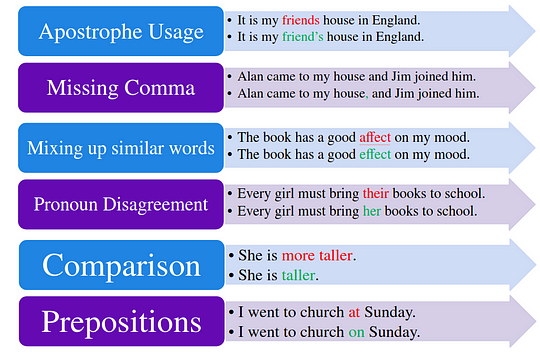
The errors encountered in written language can be of different types as shown in the image below.
Dataset
For the training of our Grammar Corrector, we use the C4_200M dataset recently released by Google. This dataset consists of 200MM examples of synthetically generated grammatical corruptions along with the correct text.
One of the biggest challenges in GEC is getting a good variety of data that simulates the errors typically made in written language. If the corruptions are random, then they would not be representative of the distribution of errors encountered in real use cases.
To generate the corruption, a tagged corruption model is first trained. This model is trained on existing datasets by taking as input a clean text and generating a corrupted text. This is represented in the figure below.

For C4_2OOM dataset, the authors first determined the distribution of relative type of errors encountered in written language. When generating the corruptions, they were conditioned on the type of error. As shown in figure below, the corruption model was conditioned to generate a determiner type error.

This allows the C4_200M dataset to have a diverse set of errors reflecting their relative frequency in real-world applications. To learn more about the process for generating synthetical corruptions, please refer to the original paper here.
For the purpose of this blog, we extracted 550K sentences from C4_200M. The C4_200M dataset is available on TF datasets. We extracted the sentences we need and saved them as a CSV. The data prep code for this is pushed to Colab here. If you are interested in downloading the prepared datasets, those can be accessed here.
A screenshot of the C4_200M dataset is below. The input is the incorrect sentence and the output is the grammatically correct sentence. These random examples show that the dataset covers inputs from different domains and a variety of writing styles.

Model Training
We will use the ever-versatile T5 model from Google for this training.
T5 is a text-to-text model meaning it can be trained to go from input text of one format to output text of one format. I have personally used this model with many different objectives like summarization (see blog here) and text classification (see blog here). And also used it to build a trivia bot that can retrieve answers from memory without any provided context. Check this blog here.
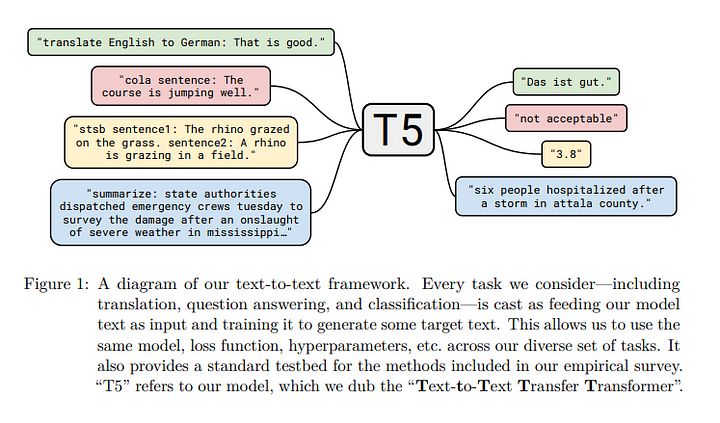
I prefer T5 for a lot of tasks for a few reasons — 1. Can be used for any text-to-text task, 2. Good accuracy on downstream tasks after fine-tuning, 3. Easy to train using Huggingface
The full code for training the T5 model on 550K examples from C4_200M is available here on Colab. Also shared on my Github here.
The high-level steps for training include:
- Tokenizing the data
We set the incorrect sentence as the input and the corrected text as the label. Both the inputs and targets are tokenized using the T5 tokenizer. The max length is set to 64 since most of the inputs in C4_200M are sentences and the assumption is that this model will also be used on sentences. The snippet of the code that does the tokenization is below.

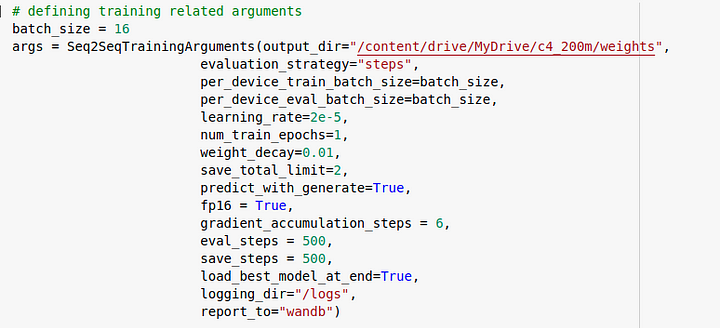
2. Training the model using seq2seq trainer class
We use the Seq2Seq trainer class in Huggingface to instantiate the model and we instantiate logging to wandb. Using weights and biases with HuggingFace is very simple. All that needs to be done is to set report_to = “wandb" in the training arguments.
3. Monitoring and evaluating the model
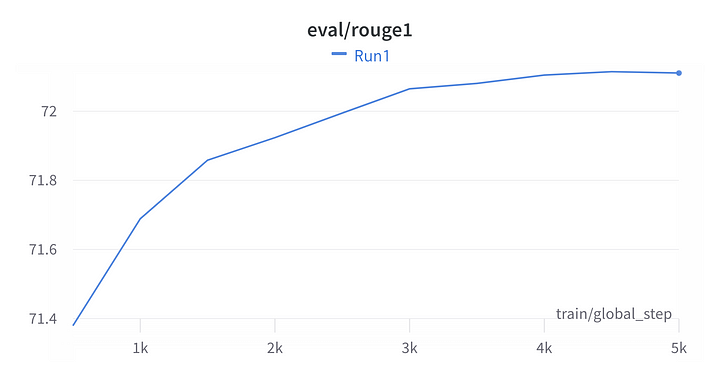
We have used the Rouge score as the metric for evaluating the model. As seen in the plots below from W&B, the model gets to a rouge score of 72 after 1 epoch of training.
This project can be accessed on Weights and Biases here.
Publishing the model on Spaces
We have pushed the trained model on Spaces here so it can be tested. As shown in the screenshot below, it can be programmed to return up to 2 corrected sequences.
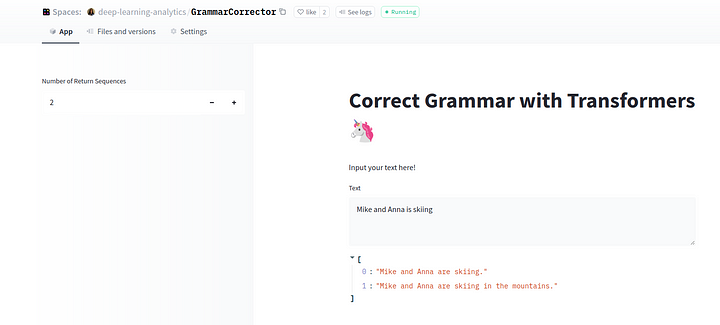
I have tested this model on many incorrect sequences and have been happy with its performance.
The model is also available on hugginface.co here and can be used directly too. The model documentation shows the steps involved in using the model.
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
model_name = 'deep-learning-analytics/GrammarCorrector'
torch_device = 'cuda' if torch.cuda.is_available() else 'cpu'
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name).to(torch_device)
def correct_grammar(input_text,num_return_sequences):
batch = tokenizer([input_text],truncation=True,padding='max_length',max_length=64, return_tensors="pt").to(torch_device)
translated = model.generate(**batch,max_length=64,num_beams=num_beams, num_return_sequences=num_return_sequences, temperature=1.5)
tgt_text = tokenizer.batch_decode(translated, skip_special_tokens=True)
return tgt_texttext = 'He are moving here.'
print(correct_grammar(text, num_return_sequences=2))Conclusion
This blog shows how easy it is to leverage HuggingFace and WandB to train NLP models for different use cases. I hope you try the HuggingFace Spaces and share any comments below about your experiences.
At Deep Learning Analytics, we specialize in building custom machine learning models for a variety of use cases. We have partnered with clients around the world to build solutions for their specific needs. Our expert team has experience with text classification, translation, summarization, neural search and a lot more. Email us at info@deeplearninganalytics.org if you see an opportunity to collaborate.