
Introduction
In collaboration with Allen AI, White House and several other institutions, Kaggle has open sourced COVID-19 open research data set (CORD-19) . CORD-19 is a resource of over 52,000 scholarly articles, including over 41,000 with full text, about COVID-19, SARS-CoV-2, and related coronaviruses. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
At Deep Learning Analytics, we have been spending time, trying different NLP techniques on this data set. In this blog, we show how you can use cutting edge Transformer based summarization models to summarize research papers related to COVID-19. This can be quite useful in getting a quick snapshot of the research paper or sections of it to decide whether you want to fully read it. Please note that I am not a health professional and the opinions of this article should not be interpreted as professional advice.
We are very passionate about using data science and machine learning to solve problems. Please reach out to us through here if you are a Health Services company and looking for data science help in fighting this crisis. Original full story published on our website here.
What is Summarization ?
According to Wikipedia, Summarization is the process of shortening a set of data computationally, to create a subset (a summary) that represents the most important or relevant information within the original content. Summarization can be applied to multiple data types like text, images or video. Summarization has been used many practical applications — summarizing articles, summarizing multiple documents on the same topic, summarizing video content to generate highlights in sports etc.
Summarization in text, specifically, can be extremely useful as it saves the users having to read long articles , blogs or other pieces of text. There can be different types of summarization as shown in the figure below which is borrowed from this blog.
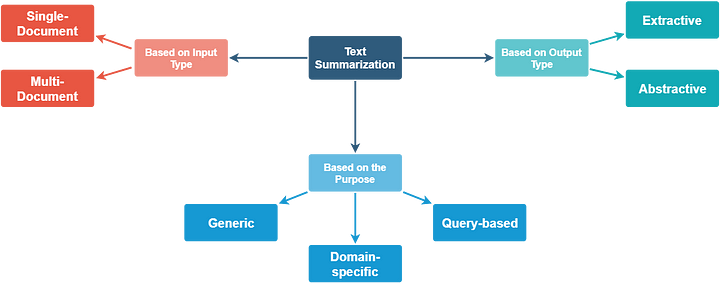
There are multiple types of summarizations — based on input type, based on desired output or purpose. The input to summarization can be single or multiple documents. Multi document summarization is a more challenging tasks but there has been some recent promising research.
The summarization task can be either abstractive or extractive. Extractive summarization creates a summary by selecting a subset of the existing text. Extractive summarization is akin to highlighting. Abstractive summarization involves understanding the text and rewriting it. You can also read more about summarization in my blog here.
Summarization of news articles using Transformers
We will be leveraging huggingface’s transformers library to perform summarization on the scientific articles. This library has implementations of different algorithms.
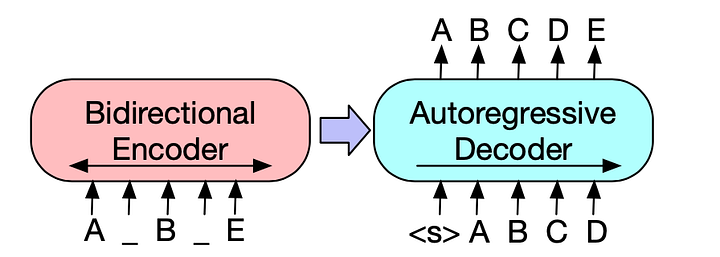
In this blog, we will be using the BART algorithm. BART is a denoising autoencoder for pretraining sequence-to-sequence models. As described in their paper, BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. As a result, BART performs well on multiple tasks like abstractive dialogue, question answering and summarization. Specifically, for summarization, with gains of up to 6 ROUGE score.
Lets test out the BART transformer model supported by Huggingface. This model is trained on the CNN/Daily Mail data set which has been the canonical data set for summarization work. The data sets consists of news articles and abstractive summaries written by humans. Before we run this model on research papers, lets run this on a news article. The following code snippets can be used to generate summary on a news article
from transformers import pipeline
summarizer = pipeline(“summarization”)

print(summarizer(ARTICLE, max_length=130, min_length=30))
Running the summarization command generates the summary below.
Liana Barrientos has been married 10 times, sometimes within two weeks of each other. Prosecutors say the marriages were part of an immigration scam. She pleaded not guilty at State Supreme Court in the Bronx on Friday.
In my opinion this is a very good short summary of the news article.The max_length parameter can be adjusted to get longer summaries.
Summarization of COVID-19 research papers
Many scientists and researchers across the globe are working on understanding more about the virus to develop effective treatments which can include vaccines or drugs to reduce the severity of attack. Our knowledge on this topic keeps increasing. AI can help humans prioritize their time effectively if it can do a first pass of reading through the research and providing a good summary. However summarization tends to be a difficult and subjective task. To truly summarize AI needs to understand the content which is difficult due to the large variation in writing styles of researchers. In this blog we evaluate how well the BART Transformer model does in summarizing the content of COVID-19 papers.
To get a clean data set of CORD-19 research papers, we will be using the dataframe biorxiv_clean.csv from here. Big thanks for xhulu on Kaggle for creating this.
Lets get started with summarizing research papers!
## Read the data frame import pandas as pd data = pd.read_csv('biorxiv_clean.csv')
Once we read the dataframe, data looks like this:
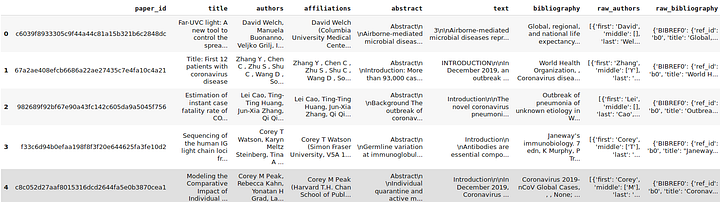
The key columns we have are paper_id, title, abstract, authors, text, bibliography etc.
Then, we will just loop through the dataframe and generate summaries. As we can see, the column ‘text’ has the scientific text in the dataframe.
from transformers import pipeline
summarizer = pipeline(“summarization”)
for i, text in enumerate(data):
print(summarizer(data[‘text’].iloc[i], max_length=1000, min_length=30))
You can experiment with min and max length parameters. We chose the above values since it provides the best results.
COVID-19 research summarization results
Some examples of these summaries are:
Text:
https://www.mdpi.com/2076-0817/9/2/107
Summary generated by BART Transformer:
Strongyloidiasis is a prevailing helminth infection ubiquitous in tropical and subtropical areas. However, prevalence data are scarce in migrant populations. This study evaluated the prevalence of this infection in people being attended in six Spanish hospitals. The prevalence was around 9%, being higher in Africa and Latin America compared with other regions. In addition, the prevalence in patients with an impaired immune system was lower compared with people non suffering immunosuppression.
Text:
https://www.biorxiv.org/content/10.1101/2020.02.22.961268v1
Summary generated by BART Transformer:
Transcription polymerase chain reaction (RT-PCR) is a standard and routinely used technique for the analysis and quantification of various pathogenic RNA. After the outbreak of COVID-19, several methods and kits for the detection of SARS-CoV-2 genomic RNA have been reported. Traditional methods consume a large number of operators, but give low diagnosis efficiency and high risk of cross infection. Magnetic nanoparticles (MNPs)-based extraction methods are centrifuge-free and have proven to be easy to operate and compatible to automation.
Observations:
Overall, I think the BART model that is trained on CNN/Daily Mail data has mixed performance. It does provide a coherent summary which is factually correct but if this summary is compared to the abstract of the paper, then we see some gaps:
- It may miss out on some key approaches or other related metadata that the researchers might want to see as a part of the summary.
- Summary tends to be shorter than the abstract on the paper and also weaker in terms of conclusion
- The embeddings used in BART model are trained on regular english vocabulary and may not be correctly understanding the scientific jargon here
In order to address these challenges the best way would be finetune the BART model on text and abstracts extracted from the above data frame. We started doing this but couldn’t continue forward much due to the intense compute requirements for training a good summarization model.
Conclusion
In this article, we see that pretrained BART model can be used to extract summaries from COVID-19 research papers. Research paper summarization is a difficult task due to scientific terminology and varying writing styles of different researchers. The BART model does quite well in generating summaries of the paper. Its limitation though is that it may not cover all the salient points.
At Deep Learning Analytics, we are extremely passionate about NLP, Transformers and deep learning in general. We have helped many startups deploy innovative AI based solutions. Check us out at — https://deeplearninganalytics.org/. This article was written by Faizan Khan and Priya Dwivedi at Deep Learning Analytics.
References
- Transformer Model Paper: https://arxiv.org/abs/1706.03762
- BART Paper — https://arxiv.org/abs/1901.07504
- CORD-19 Research Data set — https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge
- Hugging Face