BERT, a pre-trained Transformer model, has achieved ground-breaking performance on multiple NLP tasks. Very recently I came across a BERTSUM – a paper from Liu at Edinburgh. This paper extends the BERT model to achieve state of art scores on text summarization. In this blog I explain this paper and how you can go about using this model for your work.
Introduction
Single-document text summarization is the task of automatically generating a shorter version of a document while retaining its most important information. The task has received much attention in the natural language processing community. Since it has immense potential for various information access applications. Examples include tools which digest textual content (e.g., news, social media, reviews), answer questions, or provide recommendations. The summarization model could be of two types:
- Extractive Summarization — Is akin to using a highlighter. We select sub segments of text from the original text that would create a good summary
- Abstractive Summarization — Is akin to writing with a pen. Summary is created to extract the gist and could use words not in the original text. This is harder for machines to do
The performance of a text summarization system is measured by its ROUGE score. ROUGE score measures the overlap between predicted and ground truth summary.
BERT is a powerful model that has proven effective on a variety of NLP tasks. BERT’s key technical innovation is applying the bidirectional training of Transformer, a popular attention model, to language modelling. Its success shows that a language model which is bidirectionally trained can have a deeper sense of language context and flow than single-direction language models. Here is an excellent link to learn more about BERT.
BERT can also be used for next sentence prediction. The model receives pairs of sentences as input and learns to predict if the second sentence in the pair is the subsequent sentence in the original document. During training, 50% of the inputs are a pair in which the second sentence is the subsequent sentence in the original document. While in the other 50% a random sentence from the corpus is chosen as the second sentence.
Extractive Text Summarization using BERT — BERTSUM Model
The BERT model is modified to generate sentence embeddings for multiple sentences. This is done by inserting [CLS] token before the start of the first sentence. The output is then a sentence vector for each sentence. The sentence vectors are then passed through multiple layers that make it easy to capture document level features. The final summary prediction is compared to ground truth and the loss is used to train both the summarization layers and the BERT model.
Figure below shows the model architecture
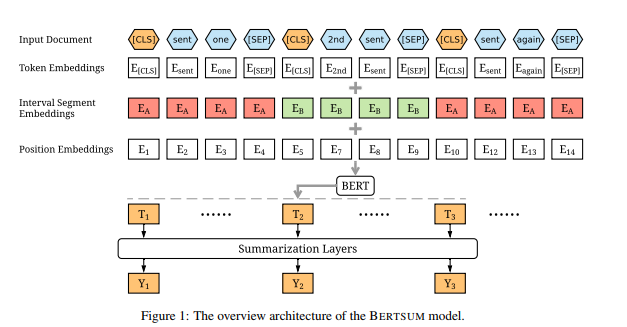
The model is trained on the CNN/Daily Mail and NYT annotated corpus. Since the ground truth data from both the corpus is abstractive summarization, a new ground truth is created. A greedy algorithm is used to generate an oracle summary for each document. The algorithm greedily select sentences which can maximize the ROUGE scores as the oracle sentences. We assigned label 1 to sentences selected in the oracle summary and 0 otherwise.
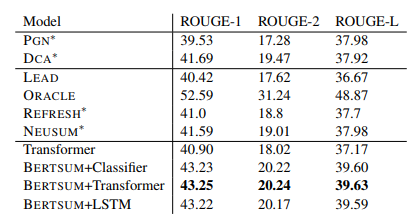
Results from BERTSUM text summarization
The paper shows very accurate results on text summarization beating state of the art abstractive and extractive summary models. See table below. Here the first row is pointer generator model explained in more detail in my blog here.
Pulling the code and testing this out
The author has generously open sourced their code at this Github. Model is implemented in Pytorch. We trained and tested the model and were happy with the results.
Please reach out to us if you see applications for Text Summarization in your business.