
Semantic segmentation is the process of associating each pixel of an image with a class label, (such as flower, person, road, sky, ocean, or car). This detailed pixel level understanding is critical for many AI based systems to allow them overall understanding of the scene. Examples include for robotics, the robotic arm may need to know exact pixel locations of the different objects it is interacting with. Another powerful use case is self-driving cars. Detailed scene understanding as shown below can help the car understand the extent of the road, figure out where other cars are in the same lane or adjacent lanes, understand if humans are on the scene and look out for traffic signs too!

Semantic Segmentation for self driving car
Semantic Segmentation vs Instance Segmentation
Often times the words semantic and instance segmentation are used interchangeably. There is a difference between them which is very well explained by the image below. If all examples of the same class are coloured the same, then we are dealing with semantic segmentation else with instance segmentation
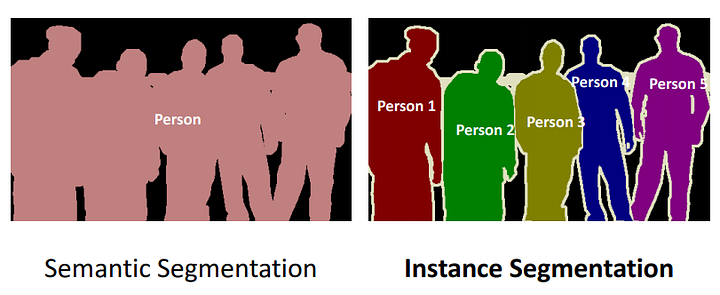
Semantic vs Instance Segmentation
Common Models used for Semantic Segmentation
There are several models that are quite popular for semantic segmentation. These include:
I have explained all these models in my blog here. I have also built several custom models using them. Please refer to this blog from me which explains how to build a Mask RCNN for car damage detection.
One observation that I had so far is that as with many deep learning based systems there is a trade off between speed and accuracy. Most of the accurate semantic segmentation models that I built were quite slow to run making them impractical for real time applications like robotics and self driving cars. So in this blog I want to talk about my experience with a semantic segmentation model that runs at 30 fps!
Using DeepLab v3 for real time semantic segmentation
I recently tested the Deep Lab V3 model from the Tensorflow Models folder and was amazed by its speed and accuracy. I think this model can prove to be a powerful option for real time semantic segmentation.
I want to focus this blog on how to access this model and test it on your images and videos. But before we go there a little bit about Deep Lab V3 architecture.
The Deeplab V3 model combines several powerful concepts in computer vision deep learning —
1. Spatial Pyramid pooling — Spatial pyramid architectures help with information in the image at different scales i.e small objects like cats and bigger objects like cars. Spatial pyramid pooling networks generally use parallel versions of the same underlying network to train on inputs at different scales and combine the features at a later step.
2. Encoder-Decoder architectures — This has become a very popular architecture for a variety of tasks in computer vision and NLP. We used the encoder to downscale the image to a feature vector that summarizes the essence of the image and then use a decoder to expand the summarized feature vector back into the dimensions of the image however the decoder would return us back an image with semantic segmentation
3. Atrous convolutions — DeepLab uses atrous convolutions. Atrous convolutions require a parameter called rate which is used to explicitly control the effective field of view of the convolution. Image below shows atrous convolutions. The benefit of atrous convolutions is they can capture information from a larger effective field of view while using the same number of parameters and computational complexity.
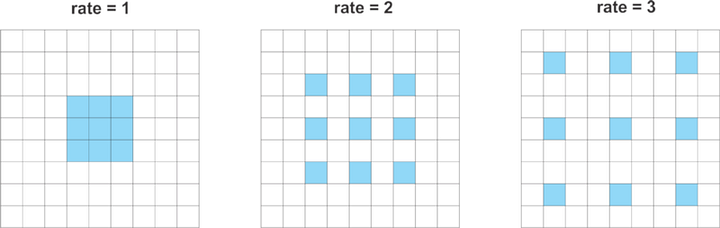
Atrous Convolutions Explanation
For more detailed explanation of model architecture, please refer to the blog here which has provided an excellent explanation.
Installing Deep Lab V3
- Git clone tensorflow/models
- Follow package installation and testing instruction in this README
Alternatively, if you have never worked with tensorflow/models before, please git pull my repo. I have included here all the support files you need, code for testing on images and videos and test images + videos
Testing DeepLab V3 on images and videos
- Picking a model — The deeplab V3 model has about 6 pretrained models available in their model zoo. These include models with mobilenet backbone and those with xception backbone. For my experimentation, I chose the mobilenetv2_coco_voctrainval model. The code notebook will automatically download this model.
- Run mobilenet deeplab v3 on video and images — For complete code please refer to my notebook on github. This notebook has modified the standard code in tensorflow repo and extended it to do inference on videos as well.
Please see inference results on some images that are not part of training set.

Semantic Segmentation on Soccer Players

Semantic Segmentation on person, dog and horse
The model performs quite well on them
We also tested the model on a few videos. Amazingly the model runs at 30 fps!

DeepLab V3 output on a video
As can be seen here the model performs quite well in identifying the pixel locations of the sheep. It does make some errors in the class assigned to it. Also runs at 30 fps!. I think the speed gives it tremendous practical application. The class wise accuracy can be improved by training this model on a specific data for a use case.
DeepLab V3 model can also be trained on custom data using mobilenet backbone to get to high speed and good accuracy performance for specific use cases.
Conclusion
- Deep Lab V3 is an accurate and speedy model for real time semantic segmentation
- Tensorflow has built a convenient interface to use pretrained models and to retrain using transfer learning
I hope you pull the code on github and test this model for yourself. I have my own deep learning consultancy and love to work on interesting problems. I have helped many startups deploy innovative AI based solutions. If you see an opportunity to collaborate then reach out to at — https://deeplearninganalytics.org/contact-us/