Deep Learning for Computer Vision
Background
Deep Learning has had a big impact on computer vision. The dramatic 2012 breakthrough in solving the ImageNet Challenge by AlexNet is widely considered to be the beginning of the deep learning revolution of the 2010s: “Suddenly people started to pay attention, not just within the AI community but across the technology industry as a whole.”. Figure below shows the error rate on ImageNet for the 10 best entries per year.
You can get access to deep learning for computer vision – for object detection, classification, localization, instance segmentation, activity recognition in videos, difference detection in images, pose recognition and many other applications. If you are interested or looking for a partner to apply deep learning for computer vision to your business, please contact us to discuss your use case.
I personally think this is a very inspiring graph of our progress in analyzing image data. The winners of ImageNet have been powerful models that are now commonly used as a starting point for transfer learning — This includes big names like VGGNet (2013), GoogleNet(2014), Inception module (2014) and ResNet(2015).
Computer Vision using deep learning is huge passion for me. I have experience using deep learning for a variety of tasks:
Image Classification
Image Classification is the task for assigning a label to an image. This is useful when there is a single class in the image and is distinctly visible in the image. Canonical example is classification of cat vs dog. Image classification models have come a long way in the last 2–3 years. We can now use transfer learning to take a subset of a well performing architecture like mobilenet, resnet etc, decide how many of its layers to freeze (not be trainable), add custom layers on top of a frozen network and create a new network quickly. These models have a huge advantage that they can be trained on relatively small amount of data. Small depends on the problem but sometimes as little as 200 images per class. At deeplearninganalytics, we have used transfer learning to train many image classification models with high accuracy.
One practical example is classifying traffic signs which is very useful for self driving cars. I trained a model that could detect signs as well as humans. If you are interested in learning more, please checkout my blog on this topic. And my github link for you to pull the code and try for yourself.
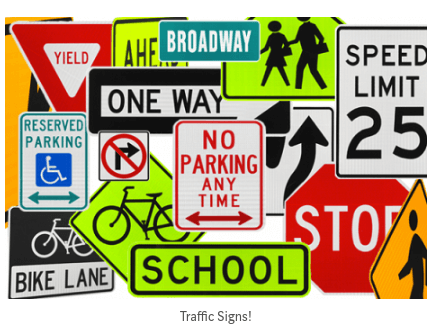
Image Classification
Another example can be detecting if a car is in parking spot or not, that is if a parking spot is occupied or not. My blog here discusses how to build this type of model. I had collected only a few hundred images of parking spot for this blog and used transfer learning.
Object Detection
Object Detection is another huge area for application of computer vision models. The difference between classification and detection is that in detection there could be multiple instances of the same class or different classes in the same image. While classification just outputs what the likely class of the image is, detection goes one step further and draws a bounding box on the image. Example would be an image with both cat and dog with bounding boxes around them.

Object Detection
Tensorflow Object Detection repo is my favourite way of building object detection models and I build them using it very regularly. I have a lot of experience building SSD and Faster RCNN models with different backbone architectures like Inception, Mobilenet, Resnet etc. I find object detection can solve a variety of practical problems across many industries like retail. manufacturing, media etc. If you rethink how to present things to the model, you can also use it in situations where there clearly in no object but an action. See object detection COCO model in action below
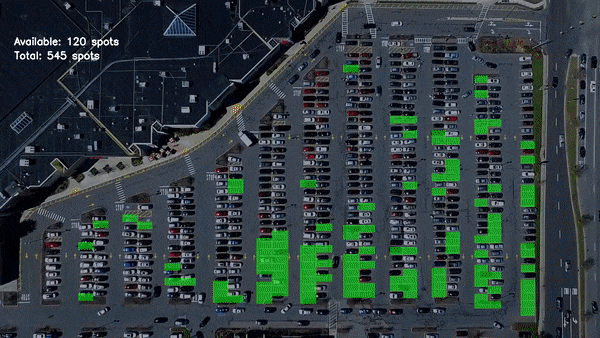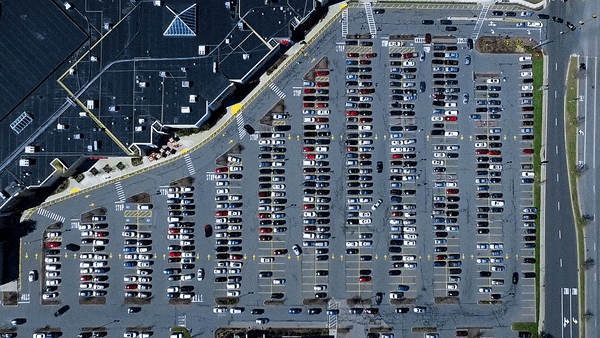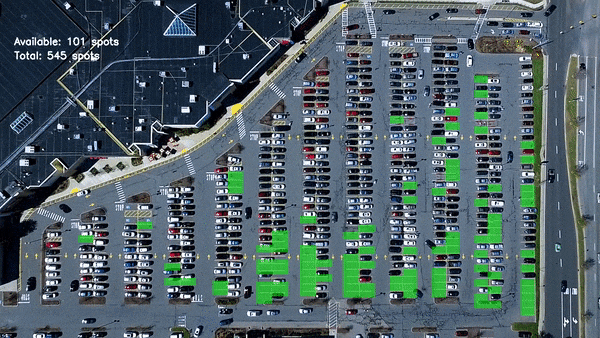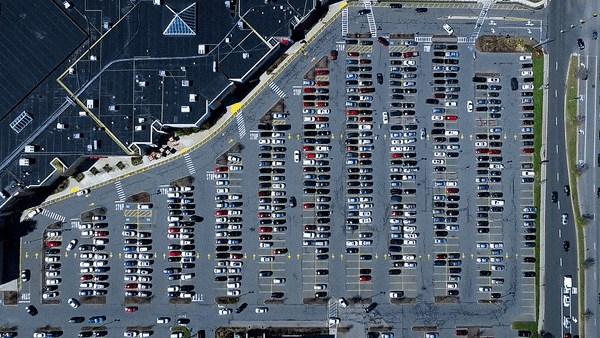
Real time parking spot detection
If you are interested in getting started on object detection, please refer to my blogs – here
and
here.
Object Tracking
Once an object is detected it can be tracked across a video. So in some sense object detection can then be extended to object tracking. As an example see blog here related to soccer player tracking and team identification.

Tracking of soccer players
However deep learning based approaches can be slow computationally and maybe an overkill in situations. They have the limitation of requiring a model to be first trained. Another approach can be to use opencv techniques like optical flow to understand which pixels are in motion. This only works against a stationary background and requires a fair bit of parameter tuning but is still a more practical approach if you want to track a variety of objects.
Object tracking can be very useful in sports especially as it can be used to track players and calculate their statistics.
Instance Segmentation
Instance segmentation models have also recently become a very popular class of models. These models are an extension of object detection where they detect multiple classes in an image but instead of outputting a bounding box they define pixel by pixel location of an object. See example below:

Semantic Segmentation
The exact pixel location can be very important in certain applications like self driving cars where we may need to know exact location of road pixels or of other cars. They are work better than object detection in situations that involve damage assessment. I have used both Tensorflow Object Detection repo and Matterport for build Mask RCNN models. I have also built lighter weight Mask RCNN models. If you are interested in building a mask model yourself, please follow my blog here which I built a Mask RCNN for car damage detection.

Car Damage Detection
There are many other type of deep learning computer vision models that can be used for activity recognition in videos, difference detection in images, pose recognition etc. If you are interested, please contact us to build a custom model for you.